Company research is a big industry, and a task that every executive performs every day. What companies to buy, which competitors are upcoming, what are key industry influencers and decision makers saying.
I thought it would be fun for us to explore the different ways we can build a company research agent. This will give us some insight on
- Data ingestion methods: how do you pull data from PDFs, large web pages, and search engines?
- Research plan: for a user question, where do we find the answers? How can we use a LLM to plan this?
- Content generation: once we have some answers, how do we create a great visualisation of everything that’s going on?
What is company research?
First, let’s talk about the definition of company research.
Company research analyzes a firm's financials, market position, and risks to guide investments, partnerships, and strategy. Conducted by investors, analysts, and strategists, it delivers high ROI by identifying opportunities and mitigating risks.
How do you conduct company research?
I often find it useful when building AI agents to understand how people do it without AI.
In my exploration, it seems like most company research comes from gathering financial reports, industry data, and news to analyze a firm's performance, risks, and market position.
With the raw data, there is then financial analysis, competitive benchmarking, industry assessment, SWOT evaluation, and management review.
Finally, insights are synthesized to guide investments, partnerships, and strategy.
Armed with this context, let’s build our company research agent. Just as an example, we are going to try to summarise the supply chain operations of PepsiCo.
Part 1: Gathering data
PDF: the annual report
Easiest place to start is Pepsi’s annual report. The latest one seems to be from 2024, about the full year results of 2023. Ingesting the PDF is fine, but we already notice a few challenges that will come our way:
 We need a large pie model for this.
We need a large pie model for this.
Correctly extracting information from graphs like above would be key.
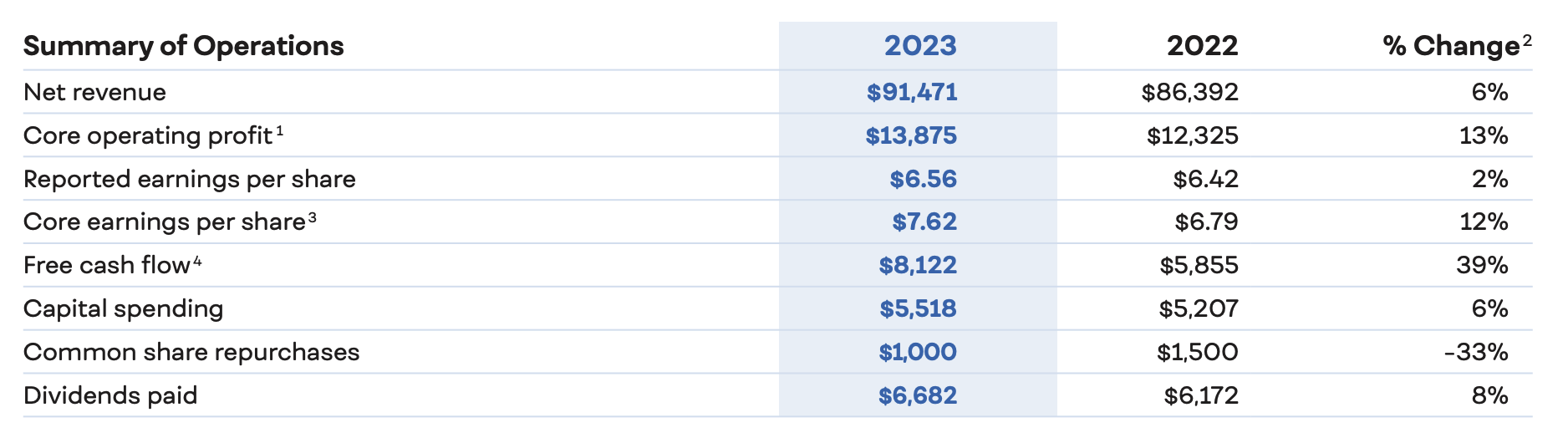 A multi modal model would help, that's a good article idea for next time.
A multi modal model would help, that's a good article idea for next time.
There are loads of tables that needs proper parsing.
In any case, PDF extraction challenges and relevant tools will be an article for the future. We know that there are choices like PyMuPDF, PyPDF, unstructured.io; Of course, you can also go with paid options like AWS Textract.
For now, let’s go with PyMuPDF. Their documentation is so easy to understand. We install the package with pip install --upgrade pymupdf , then its just a few lines of code to get started:
import pymupdf
doc = pymupdf.open("2023-pepsico-annual-report.pdf")
for page in doc: # iterate the document pages
text = page.get_text().encode("utf8") # get plain text (is in UTF-8)
print(text)
doc.close()
It works, but the output is less than readable in the terminal:
 Wall of text, gah!
Wall of text, gah!
Fortunately, Datograde enables us to work with large documents like a PDF easily. Let’s log this to Datograde, using markdown to shortcut some of the text formatting that we are getting from PyMuPDF :
import pymupdf
import os
from datograde import Datograde
datograde = Datograde(access_token=os.getenv("DATOGRADE_API_KEY"))
doc = pymupdf.open("2023-pepsico-annual-report.pdf")
text = "\n".join([page.get_text() for page in doc])
doc.close()
with open("2023-pepsico-annual-report.pdf", "rb") as f:
pdf_content = f.read()
response = datograde.attempt(
new_input_files=[(pdf_content, "pdf")], # log the PDF to the input column
files=[(text, "md")], # log the text output
track_id="[redacted]",
)
Well, this looks way better:
 Inputs and outputs side by side
Inputs and outputs side by side
Similarly we can extract all the tables with a few more lines of code.
...
tables = []
for page in doc:
tables.extend(page.find_tables())
...
response = datograde.attempt(
new_input_files=[(pdf_content, "pdf")],
files=[(text, "md")] + [(table.to_markdown(), "md") for table in tables],
track_id="[redacted]",
)
Then log each one on its own to Datograde as markdown files. PyMuPDF clearly struggles with tables in PDFs, especially when compared to a state of the art offering like AWS Textract. In the next attempt, we will start skipping this, but now you know how it can be done.
 PyMuPDF gave us way too many tables
PyMuPDF gave us way too many tables
Webpage: the ‘Mission and Vision’
Let's add some more context to our agent. We can do this by adding a webpage. A good webpage for this kind of research is a company's "mission and vision" page.
We just need to request the right webpage, then add it to our input panel:
# Fetch webpage content
url = "https://www.pepsico.com/who-we-are/mission-and-vision"
webpage_response = requests.get(url)
html_content = webpage_response.text
# new attempt call
response = datograde.attempt(
new_input_files=[
(pdf_content, "pdf"),
(html_content, "html") # Add the HTML content
],
files=[(text, "md")] + [(table.to_markdown(), "md") for table in tables],
track_id="[redacted]",
)
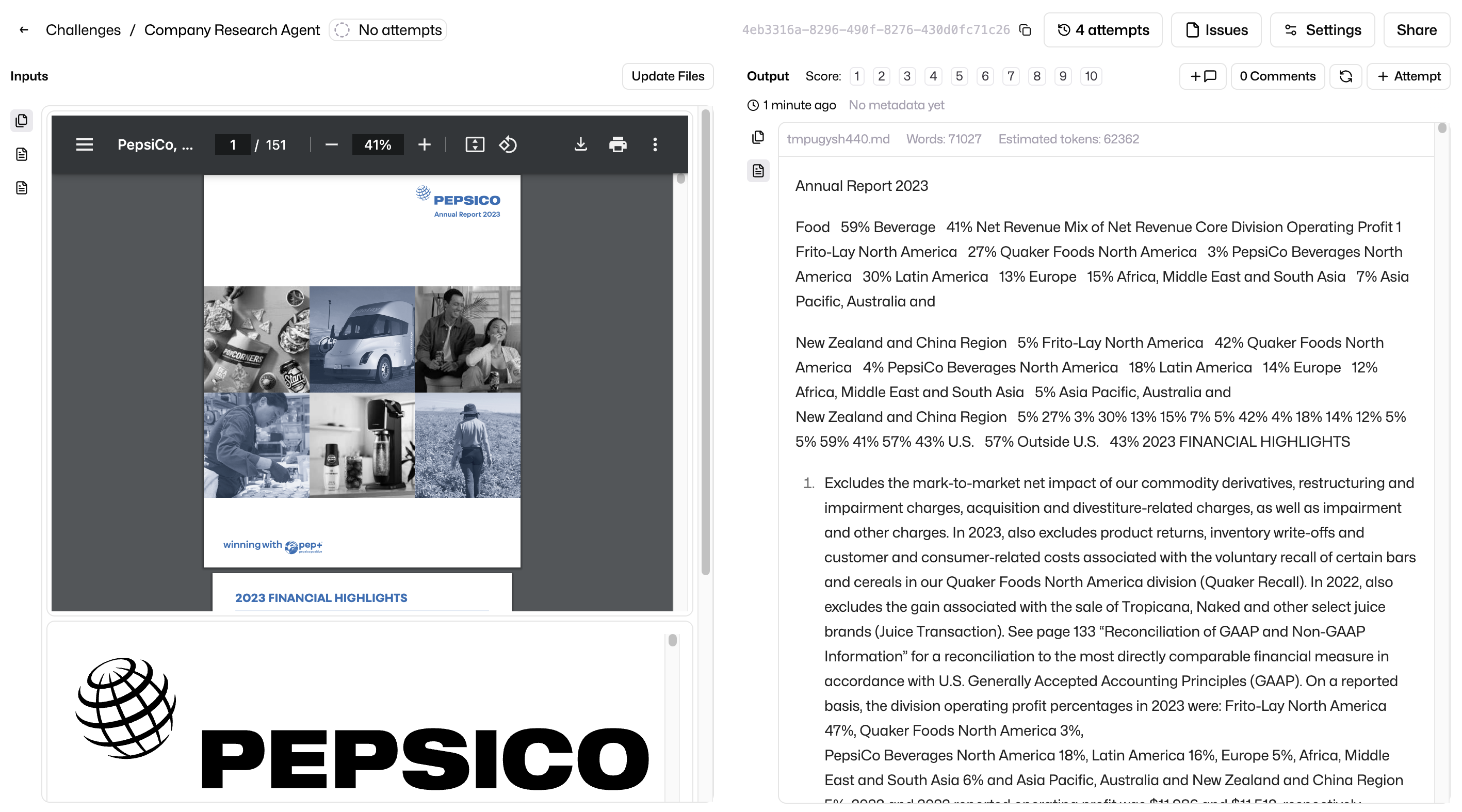 More intel, better research
More intel, better research
That’s very useful. There are many things we can do to make this better, for example also pulling in quarterly reports, interesting PDFs from the company website, news articles etc. But for now, let’s move onto building the agent that looks through this data.
Part 2: Research
A dummy RAG (retrieval augmented generation) system
Because there is a lot of raw information, we can’t just feed all of it into a LLM. Google’s Gemini may boast a context window of 2 million tokens, but we know that effective context doesn’t work the same way.
The typical way to do this will be to use a vector database. You chunk the data up, embed them using an embedding service, then index it in a vector database. That’s so much work though! Instead, to showcase the basic concepts, we are just going to chunk the data simply and use an agentic trick to not depend on vector databases.
Before that trick, let's extract the text from the webpage. There is a nifty tool from Jina.ai that does this. All you need to do is prepend r.jina.ai to any URL, and it’ll give you back a markdown. Amazing! No Javascript rendering support, though.
# Fetch webpage content, just the text
url = "https://r.jina.ai/https://www.pepsico.com/who-we-are/mission-and-vision"
webpage_response = requests.get(url, headers=headers)
md_html_content = webpage_response.text
We can then combine all the text information we have scraped, and build some convenience functions to chunk the data, and retrieve chunks that contain a particular keyword.
# Combine content from both sources
combined_content = md_html_content + "\n\n" + text
# Chunk the combined content into 1000-character pieces
chunk_size = 1000
chunks = [
combined_content[i : i + chunk_size]
for i in range(0, len(combined_content), chunk_size)
]
def find_relevant_chunks(chunks, keywords):
"""Find chunks that contain any of the keywords."""
relevant_chunks = []
for chunk in chunks:
chunk_lower = chunk.lower()
if any(keyword in chunk_lower for keyword in keywords):
relevant_chunks.append(chunk)
return relevant_chunks
Now, remember the ‘trick’ that I mentioned? Without a vector database, we cannot embed the research question as a vector, and then match relevant chunks of text using vector search. What we can do, however, is to prompt the AI to plan for a few keywords that will get us the chunks we need. Let’s do just that
Prompt for getting keywords from any research question
Given this research question: "{question}" What are the 3-5 most important keywords or phrases we should look for in company documents? Return only a JSON array of lowercase keywords/phrases.
def get_relevant_keywords(question):
"""Get relevant keywords for the research question using OpenAI."""
prompt = f"""Given this research question: "{question}"
What are the 3-5 most important keywords or phrases we should look for in company documents?
Return only a JSON array of lowercase keywords/phrases."""
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"},
)
keywords = json.loads(response.choices[0].message.content)["keywords"]
return keywords
Fantastic.
Let’s finally take the research question, and ask the agent to execute the research flow:
def analyze_chunks(question, relevant_chunks):
"""Analyze the relevant chunks using OpenAI to answer the research question."""
chunks_text = "\n\n---\n\n".join(relevant_chunks)
prompt = f"""Research Question: {question}
Based on these relevant excerpts from company documents:
{chunks_text}
Please provide a detailed answer to the research question, citing specific information from the documents where possible."""
response = client.chat.completions.create(
model="gpt-4o", messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
def research_question(question):
"""Main function to process a research question."""
# Get relevant keywords
keywords = get_relevant_keywords(question)
print(f"Looking for keywords: {keywords}")
# Find relevant chunks
relevant_chunks = find_relevant_chunks(chunks, keywords)
print(f"Found {len(relevant_chunks)} relevant chunks")
# Analyze chunks and get answer
answer = analyze_chunks(question, relevant_chunks)
return answer
question = "What is PepsiCo's strategy for sustainable packaging?"
answer = research_question(question)
print(answer)
Just to zoom in on the prompt we used:
Prompt for answering the research question based on chunks
Research Question: {question}
Based on these relevant excerpts from company documents:
{chunks_text}
Please provide a detailed answer to the research question, citing specific information from the documents where possible.
To summarise, this is how the agent works:
get_relevant_keywords: Uses OpenAI to identify key search terms from a research questionfind_relevant_chunks: Filters the document chunks based on the keywordsanalyze_chunks: Uses OpenAI to analyze the relevant chunks and answer the research questionresearch_question: Main function that orchestrates the research process
Now, let’s log the output to Datograde, so we can see it nicely
with open("2023-pepsico-annual-report.pdf", "rb") as f:
pdf_content = f.read()
response = datograde.attempt(
new_input_files=[
(pdf_content, "pdf"),
(md_html_content, "md"),
(html_content, "html"),
],
files=[(question + "\n\n" + answer, "md"), (text, "md")],
track_id="[redacted]",
)
Boom! The answer is really nice, I like how gpt-4o actually quoted back the relevant sentences found in the source material as well.
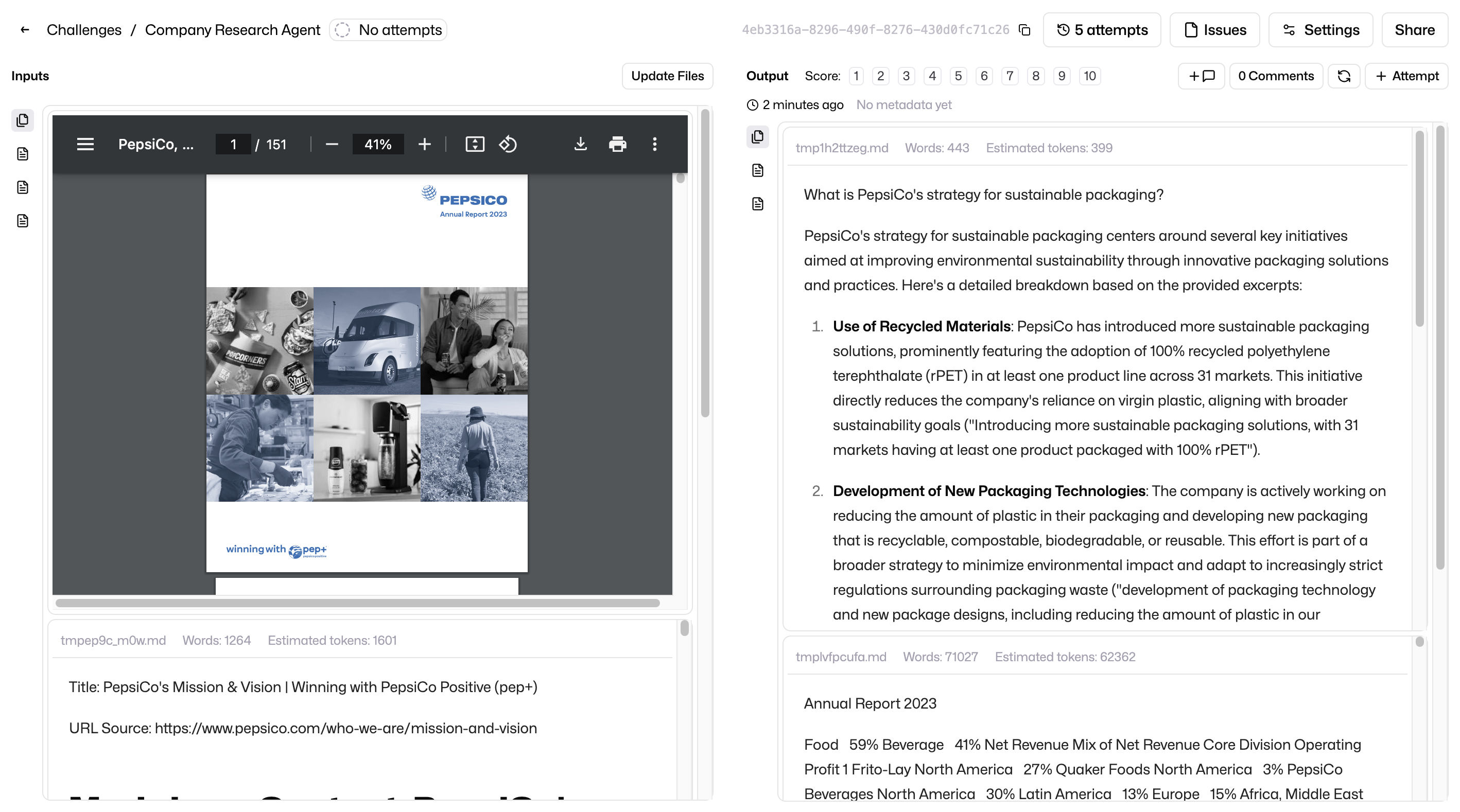 Where was this when I was in school?
Where was this when I was in school?
Visualising the RAG process
This is great, but if we really look at the results, there are areas of improvement. To improve it, let’s make sure we know how the whole pipeline got to this point. Due to the prevalence of RAG use cases, we have two specific visuals for this.
- Search results. If you log a file with a
search_resultstype, you can pass over a list of strings, or a list of objects with keystitle,snippet,score- and you can generate a search result page visualisation. - Tags. There are many ways to visualise the keywords that the AI came up with, but the easiest way is to use the
tagsvisualisation.
If we combine the two, we get the below:
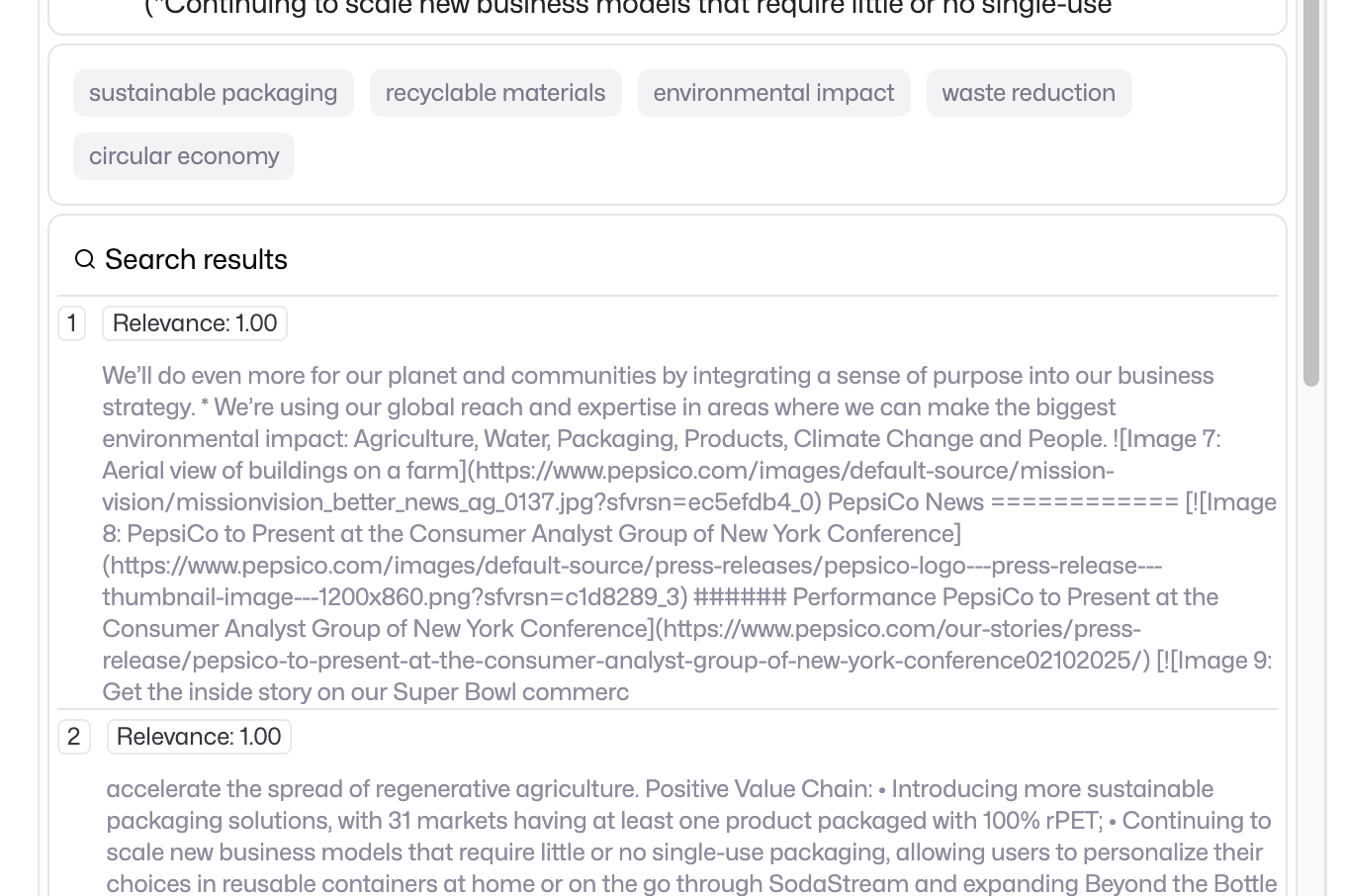 The RAG process
The RAG process
Nice!
Let’s see what code we needed to change to get here:
cot = []
def research_question(question):
"""Main function to process a research question."""
# Get relevant keywords
keywords = get_relevant_keywords(question)
print(f"Looking for keywords: {keywords}")
cot.append((keywords, "tag"))
# Find relevant chunks
relevant_chunks = find_relevant_chunks(chunks, keywords)
print(f"Found {len(relevant_chunks)} relevant chunks")
cot.append((relevant_chunks, "search_results"))
# Analyze chunks and get answer
answer = analyze_chunks(question, relevant_chunks)
return answer
question = "What is PepsiCo's strategy for sustainable packaging?"
answer = research_question(question)
print(answer)
with open("2023-pepsico-annual-report.pdf", "rb") as f:
pdf_content = f.read()
response = datograde.attempt(
new_input_files=[
(pdf_content, "pdf"),
(md_html_content, "md"),
(html_content, "html"),
],
files=[(question + "\n\n" + answer, "md")] + cot + [(text, "md")],
track_id="[redacted]",
)
Simple stuff. Let’s look at how actionable it is now to inspect what’s going on in our company research agent and improve it. What’s more interesting is that we managed to build all this without learning a new ‘agentic’ framework, in just 115 lines of code!
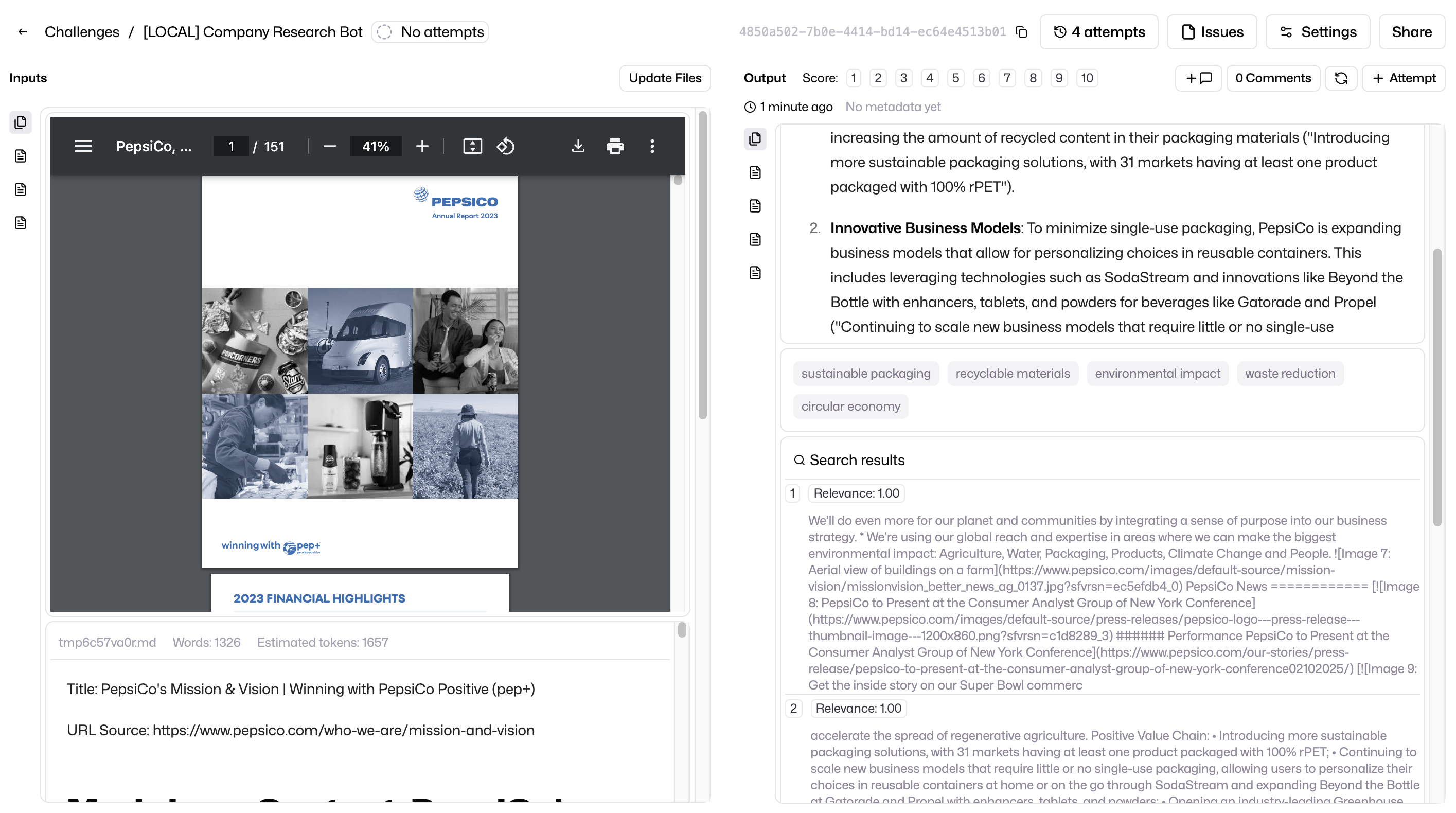 company-research-agent-8.png
company-research-agent-8.png
Here’s the code in its full glory:
import pymupdf
import os
import requests
from datograde import Datograde
from openai import OpenAI
import json
datograde = Datograde(access_token=os.getenv("DATOGRADE_API_KEY"))
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# Fetch webpage content
url = "https://www.pepsico.com/who-we-are/mission-and-vision"
webpage_response = requests.get(url, headers=headers)
html_content = webpage_response.text
# Fetch webpage content, just the text
url = "https://r.jina.ai/https://www.pepsico.com/who-we-are/mission-and-vision"
webpage_response = requests.get(url, headers=headers)
md_html_content = webpage_response.text
# Process PDF as before
doc = pymupdf.open("2023-pepsico-annual-report.pdf")
text = "\n".join([page.get_text() for page in doc])
tables = []
for page in doc:
tables.extend(page.find_tables())
doc.close()
# Combine content from both sources
combined_content = md_html_content + "\n\n" + text
# Chunk the combined content into 1000-character pieces
chunk_size = 1000
chunks = [
combined_content[i : i + chunk_size]
for i in range(0, len(combined_content), chunk_size)
]
cot = []
def get_relevant_keywords(question):
"""Get relevant keywords for the research question using OpenAI."""
prompt = f"""Given this research question: "{question}"
What are the 3-5 most important keywords or phrases we should look for in company documents?
Return only a JSON array of lowercase keywords/phrases."""
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"},
)
keywords = json.loads(response.choices[0].message.content)["keywords"]
return keywords
def find_relevant_chunks(chunks, keywords):
"""Find chunks that contain any of the keywords."""
relevant_chunks = []
for chunk in chunks:
chunk_lower = chunk.lower()
if any(keyword in chunk_lower for keyword in keywords):
relevant_chunks.append(chunk)
return relevant_chunks
def analyze_chunks(question, relevant_chunks):
"""Analyze the relevant chunks using OpenAI to answer the research question."""
chunks_text = "\n\n---\n\n".join(relevant_chunks)
prompt = f"""Research Question: {question}
Based on these relevant excerpts from company documents:
{chunks_text}
Please provide a detailed answer to the research question, citing specific information from the documents where possible."""
response = client.chat.completions.create(
model="gpt-4o", messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
def research_question(question):
"""Main function to process a research question."""
# Get relevant keywords
keywords = get_relevant_keywords(question)
print(f"Looking for keywords: {keywords}")
cot.append((keywords, "tag"))
# Find relevant chunks
relevant_chunks = find_relevant_chunks(chunks, keywords)
print(f"Found {len(relevant_chunks)} relevant chunks")
cot.append((relevant_chunks, "search_results"))
# Analyze chunks and get answer
answer = analyze_chunks(question, relevant_chunks)
return answer
question = "What is PepsiCo's strategy for sustainable packaging?"
answer = research_question(question)
print(answer)
with open("2023-pepsico-annual-report.pdf", "rb") as f:
pdf_content = f.read()
response = datograde.attempt(
new_input_files=[
(pdf_content, "pdf"),
(md_html_content, "md"),
(html_content, "html"),
],
files=[(question + "\n\n" + answer, "md")] + cot + [(text, "md")],
track_id="[redacted]",
)
Research agent in 100 lines of code
So there we have it. What can we do next?
- Data ingestion. We can add more data sources, like quarterly reports, news articles, and more.
- Research plan. We can use a LLM to plan the research process, and use the
chain-of-thoughtvisualisation to see what the agent is doing. - Content generation. We can use a LLM to generate the final answer, including graphs and tables.
Keep an eye out for the next article, where we will look at how to improve the research agent, and make it more accurate and useful.